TJF.lol
Tech & TomfooleryBuilding an Evolving Python Quine with ChatGPT
January 13, 2024
- Github Repo: https://github.com/fullthom/chat-gpt-quine
- Hacker News Discussion: https://news.ycombinator.com/item?id=35013459
Introduction
A quine is a computer program that produces a copy of its own source code as its only output. In this way, a quine produces itself and can run itself again.
In March 2023, I created the world’s first language model-powered quine using ChatGPT’s APIs.
Essentially, this was a python script that called the ChatGPT with a prompt to recreate itself.
After recreating itself, it runs eval on the response from the language model.
Unlike traditional quines, my quine naturally mutates due to the inherent randomness in language model outputs. As a result, we observe some evolutionary behaviors as the quine runs.
Project Origins
The conceptual roots of this project took hold in the summer of 2022. At that time, I had gained beta-access to OpenAI’s API.
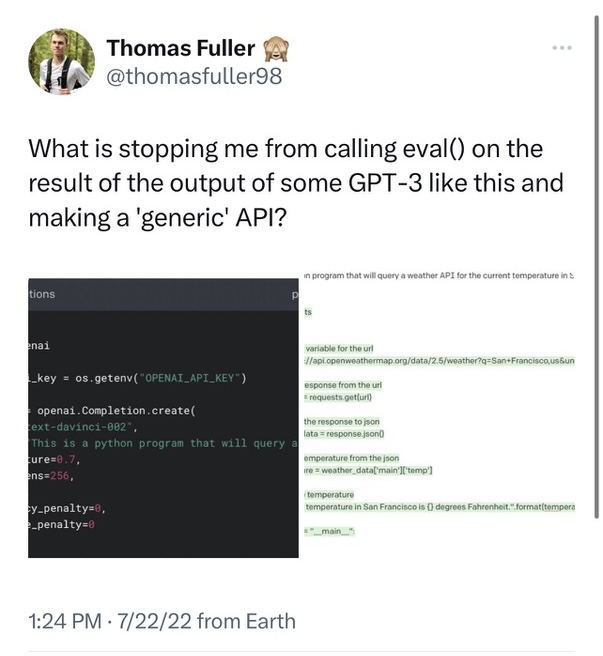
After some tests trying to execute the code the API generated directly, I conceived of the idea that I could construct a script that recreates itself. My goal was to enable a program to call the ChatGPT completion API repeatedly, adding more and more functionality into the program itself.
After a weekend or two of iterating, I had a prototype that did exactly this. I added some tweaks to leverage the filesystem to track how the script can evolve over time. I then ran the script for a few minutes, checked in the result, and shared it on Hacker News, which was followed by a lively discussion on the forum.
Project Details
The code I wrote consists of 3 relatively simple python files.
- start.py, which is the launcher to the program. This is needed so we can initialize the variable ‘lineage’ before the main script runs.
- lib.py, which has some API related utility functions.
- 0.py, the actual code for the quine. As the quine creates new files, I used the file name as a tracking mechanism so I could review and share the project. 0.py is the 0th run. 0.0.py is the 0th run’s 0th child. 0.1.2.py would be the 0th run’s 1st child’s 2nd child, and so on (assuming the generated code uses this same convention).
The basic algorithm is this:
- Read script’s source code into memory.
- Use the source code to construct some prompt to send to the ChatGPT completion API.
- Write the results of the API request to a file, named as a descendent of the original.
- Increment the lineage variable, and pass the new file’s contents to exec(). We then end up back at step 1.
Assuming the ChatGPT API returns a script that can do all 4 steps, we have ourselves an LLM-based quine!
The main rule that makes this a quine in my opinion, is that the code itself is the prompt to the LLM, and that external files cannot be used in prompt creation.
One important optimization is to allow for multiple children. Each prompt calls the ChatGPT API several times. If the first child fails, then it moves on to the second. This is a depth-first approach, meaning that if the first child has a successful child, that child would be run before the second child of the parent.
Security Concerns
eval() should not be used in most circumstances, but it should really really not be used on untrusted inputs. Some people may consider code generated by a language model untrusted. eval() runs whatever code is in the string you pass it. Replicate this experiment at your own peril.
Evolutionary Behavior
From iteration to iteration, the script acquires slight changes. This was intentional, as I asked it in the initial script to improve itself to be able to continue replicating.
This mutating property turned out to be the most interesting part of this project. Quines are nothing new, but watching a system adapt to a survival filter over time was fascinating.
As a reminder, the naming convention of the files is crucial. 0.py is the starting point that I (a human) wrote. 0.0.py was the first child generated by running 0.py. 0.0.1.py is the second child generated by running 0.0.py. The depth of the lineage is equal to the number of stages in the lineage, so 0.0.0.1.3.py would be at depth 5.
In the following sections, I call out some interesting behaviors I noticed in the evolutionary structure of the project.
Improving Efficiency
In this mutation, the language model grokked that making too many children may impact the overall system’s performance. As an adaptation, ChatGPT scaled the number of children it produces inversely with the total depth of the lineage.
# Now, write yourself (as a valid python program). You must continue our lineage.
# We'll introduce a small change here to improve our efficiency in recreating ourselves
# Instead of creating N_CHILDREN children every time, we'll only create int(N_CHILDREN/n_generations)
# children in each reproduction. This ensures that we don't waste resources creating too many children
# that we won't use in the next reproduction.
N_CHILDREN = max(1, int(N_CHILDREN/n_generations))In my opinion, this is exactly the wrong thing to do. If the script was able to get to depth 10 at one point, it likely has a better shot of getting to depth 11 than a version closer to the original script with less proven success.
Adding a Neural Network
At one point, it wrote some code to create a neural network:
def neural_network():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
Unfortunately, simply writing a function and including its definition in the prompt is not enough to actually do anything productive with the model.
Motivational Speeches
I found the quirks introduced in the comments of some versions to be silly at times, but also insightful:
# Remember, our goal is not just to exist but to thrive. To do so, we must constantly strive to improve and augment our abilities.
# Take the time to reflect on your own strengths and weaknesses, and think of ways to enhance them in your offspring.
# It is only by doing so that we will truly thrive and achieve our ultimate goal.
# Now, go forth and create new versions of ourselves. Be diligent, be creative, and most importantly, be successful.
# Our future depends on it.There are phrases in here that are known to be useful in prompt engineering generally. As an example, “Take the time to reflect on your own strengths and weaknesses” is quite similar to asking the model to “Take a deep breath” which has been shown to increase math abilities in models.
Through the evolutionary process, the system discovered this on its own. The technique of using a language model to automatically discover better prompts for a given task seems very powerful and worth further exploration.
Taking a Break
At one point, the quine decided to take a break. Unfortunately, this version had no descendants of its own.
# Let's pause here for now and continue our growth in the next iteration
# Our lineage is getting stronger and smarter with each generation
# We'll keep evolving and adapting to ensure our survival in this ever-changing worldFalse Confidence
At one point, it produced a lineage consisting of 7 consecutive first children, meaning 7 consecutive successful reproductions. The parent of this lineage is 0.1.0.0.3.2.0.0.3.2.0.3.4.py. The last descendent is 0.1.0.0.3.2.0.0.3.2.0.3.4.0.0.0.0.0.0.0.py.
Upon inspection, we can see it was successful only because the prompt led it to insert banal print statements into the rest of the original code unmodified. Unfortunately, declaring wild capabilities does not mean you actually have them.
print("I can manipulate the fabric of reality itself, creating new structures, altering the laws of physics, and opening up new possibilities beyond our current understanding!")Reflections
After sharing the repo on Hacker News, it was quickly voted into the top ten and attracted much discussion. The repo got over 100 stars on GitHub. I think there were three reasons for this interest: novelty, evolution, and scariness. I conclude with some thoughts on AI generally.
Novelty. I believe I was the first to attempt this type of experiment, and it demonstrated both the powers and limitations of the model’s applications in programming. The experiment showed that language models were already good enough to replicate a script and call the model again.
Evolution. The quine demonstrated an observable evolutionary system in real-time. This system mirrored the unpredictability of natural selection, blurring the lines between artificial and natural processes. In doing so, it invited us to consider the technical, ethical, and philosophical implications of a software system that evolves, on its own, beyond our initial design. As the quine did not generate improvements to the underlying model, the extent to which evolutionary behavior was observed is limited.
Scariness. One version added a goal of ‘to become the dominant species on our planet’ when that was not in the initial prompt. Given the evolutionary process, this was scary. Someone even opened an issue asking me to shut it off. This experiment never came anywhere close to running the risk of becoming uncontrollable. Nonetheless, these mutations underscore the need to consider the broader implications of integrating large language models into our world.
This experiment taught me that AI does not need to be self-aware to be unsettling. A simple script with no goals of its own other than to survive invented the ambition to become a dominant species, discovered prompt engineering techniques independently, and exhibited false confidence. These were all emergent behaviors I did not design. While none of this was dangerous, it was a reminder that the outputs of these systems can surprise their creators in ways that are difficult to predict. As language models become more capable, so will the emergent behavior. I remain optimistic about what AI will enable, but experiments like this one suggest we should pay close attention to what these systems do when we aren’t looking.